


Challenges and Future Directions for AI Spark Big Model
Introduction
The rapid evolution of big data technologies and artificial intelligence has radically transformed many aspects of society, businesses, people and the environment, enabling individuals to manage, analyze and gain insights from large volumes of data (Dwivedi et al., 2023). The AI Spark Big Model is one effective technology that has played a critical role in addressing significant data challenges and sophisticated ML operations. For example, the adoption of Apache Spark in various industries has resulted in the growth of a number of unique and diverse Spark applications such as machine learning, processing streaming data and fog computing (Ksolves Team, 2022). As Pointer (2024) stated, in addition to SQL, streaming data, machine learning, and graph processing, Spark has native API support for Java, Scala, Python, and R. These evolutions made the model fast, flexible, and friendly to developers and programmers. Still, the AI Spark Big Model has some challenges: the interpretability of the model, the scalability of the model, the ethical implications, and integration problems. This paper addresses the negative issues linked to the implementation of these models and further explores the potential future developments that Spark is expected to undergo.
Challenges in the AI Spark Big Model
One critical problem affecting the implementation of the Apache Spark model involves problems with serialization, precisely, the cost of serialization often associated with Apache Spark (Simplilearn, 2024). Serialization and deserialization are necessary in Spark as they help transfer data over the network to the various executors for processing. However, these processes can be expensive, especially when using languages such as Python, which do not serialize data as effectively as Java or Scala. This inefficiency can have a significant effect on the performance of Spark applications. In Spark architecture, applications are partitioned into several segments sent to the executors (Nelamali, 2024). To achieve this, objects need to be serialized for network transfer. If Spark encounters difficulties in serializing objects, it results in the error: org. Apache. Spark. SparkException: Task not serializable. This error can occur in many situations, for example, when some objects used in a Spark task are not serializable or when closures use non-serializable variables (Nelamali, 2024). Solving serialization problems is essential for improving the efficiency and stability of Spark applications and their ability to work with data and execute tasks in distributed systems.
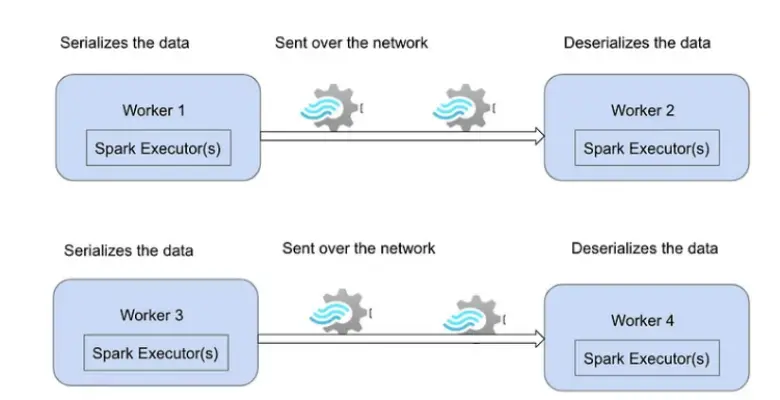
Figure 1: Figure showing the purpose of Serialization and deserialization
The second challenge affecting the implementation of Spark involves the management of memory. According to Simplilearn, 2024, the in-memory capabilities of Spark offer significant performance advantages because data processing is done in memory, but at the same time, they have drawbacks that can negatively affect application performance. Spark applications usually demand a large amount of memory, and poor memory management results in frequent garbage collection pauses or out-of-memory exceptions. Optimizing memory management for big data processing in Spark is not trivial and requires a good understanding of how Spark uses memory and the available configuration parameters (Nelamali, 2024). Among the most frequent and annoying problems is the OutOfMemoryError, which can affect the Spark applications in the cluster environment. This error can happen in any part of Spark execution but is more common in the driver and executor nodes. The driver, which is in charge of coordinating the execution of tasks, and the executors, which are in charge of the data processing, both require a proper distribution of memory to avoid failures (Simplilearn, 2024). Memory management is a critical aspect of the Spark application since it affects the stability and performance of the application and, therefore, requires a proper strategy for allocating and managing resources within the cluster.
The use of Apache Spark is also greatly affected by the challenges of managing large clusters. When data volumes and cluster sizes increase, the problem of cluster management and maintenance becomes critical. Identifying and isolating job failures or performance issues in large distributed systems can be challenging (Nelamali, 2024). One of the problems that can be encountered is when working with large data sets; actions sometimes produce errors if the total size of the results exceeds the value of Spark Driver Max Result Size set by Spark. Driver. maxResultSize. When this threshold is surpassed, it triggers the error: org. Apache. Spark. SparkException: Job aborted due to stage failure: The total size of serialized results of z tasks (x MB) is more significant than Spark Driver maxResultSize (y MB) (Nelamali, 2024). These errors highlight the challenges of managing big data processing in Spark, where complex solutions for cluster management, resource allocation, and error control are needed to support large-scale computations.
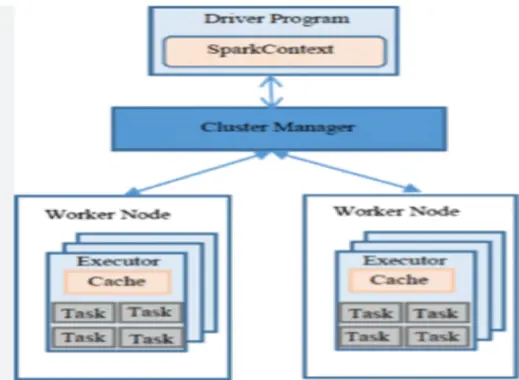
Figure 2: The Apache Spark Architecture
Another critical issue that has an impact on the Apache Spark deployment is the Small Files Problem. Spark could be more efficient when dealing with many small files because each task is considered separate, and the overhead can consume most of the job's time. This inefficiency makes Spark less preferable for use cases that involve many small log files or similar data sets. Moreover, Spark also depends on the Hadoop ecosystem for file handling (HDFS) and resource allocation (YARN), which adds more complexity and overhead. Nelamali, 2024 argues that although Spark can operate in standalone mode, integrating Hadoop components usually improves Spark's performance.
The implementation of Apache Spark is also affected by iterative algorithms as there is a problem of support for complex analysis. However, due to the system's architecture being based on in-memory processing, in theory, Spark should be well-suited for iterative algorithms. However, it can be noticed that it can be inefficient sometimes (Sewal & Singh, 2021). This inefficiency is because Spark uses resilient distributed datasets (RDDs) and requires users to cache intermediate data in case it is used for subsequent computation. After each iteration, there is data writing and reading, which performs operations in memory, thus noting higher times of execution and resources requested and consumed, which affects the expected boost in performance. Like Spark, which has MLlib for extensive data machine learning, some libraries may not be as extensive or deep as those in the dedicated machine learning platforms (Nguyen et al., 2019). Some users may be dissatisfied with Spark’s provision since MLlib may present basic algorithms, hyper-parameter optimization, and compatibility with other extensive ML frameworks. This restriction tends to make Spark less suitable for more elaborate analytical work, and a person may have to resort to the use of other tools as well as systems to obtain a certain result.
The Future of Spark
a. Enhanced Machine Learning (ML)
Since ML assumes greater importance in analyzing BD, Spark’s MLlib is updated frequently to manage the increasing complexity of ML procedures (Elshawi et al., 2018). This evolution is based on enhancing the number of the offered algorithms and tools that would refine performance, functionality, and flexibility. Future enhancements is more likely to introduce deeper learning interfaces that can be directly integrated into the Spark platform while implementing more neural structures in the network. Integration of TensorFlow and PyTorch, along with the optimized library for GPU, will be helpful in terms of time and computational complexity required for training and inference associated with high dimensional data and large-scale machine learning problems. Also, the focus will be on simplifying the user interface through better APIs, AutoML capabilities, and more user-friendly interfaces for model optimization and testing (Simplilearn, 2024). These advancements will benefit data scientists and engineers who deal with big data and help democratize ML by providing easy ways to deploy and manage ML pipelines in distributed systems. Better support for real-time analysis and online education will also help organizations gain real-time insights, thus improving decision-making.
b. Improved Performance and Efficiency
Apache Spark's core engine is continuously improving to make it faster and more efficient as it continues to be one of the most popular technologies in the ample data space. Some of the areas of interest are memory management and other higher levels of optimization, which minimize the overhead of computation and utilization of resources (Simplilearn, 2024). Memory management optimization will reduce the time taken for garbage collection and enhance the management of in-memory data processing, which is vital for high throughput and low latency in big data processing. Also, improvements in the Catalyst query optimizer and Tungsten execution engine will allow for better execution of complicated queries and data transformations. These enhancements will be beneficial in cases where large amounts of data are shuffled and aggregated, often leading to performance issues. Future attempts to enhance support for contemporary hardware, like faster storage devices such as NVMe and improvements in CPU and GPU, will only increase Spark's capacity to process even more data faster (Armbrust et al., 2015). Moreover, future work on AQE will enable Spark to adapt the execution plans at runtime by using statistics, which will enhance data processing performance. Altogether, these improvements will guarantee that Spark remains a high-performance and scalable tool that will help organizations analyze large datasets.
c. Integration with the Emerging Data Sources
With the growth of the number of data sources and their types, Apache Spark will transform to process many new data types. This evolution will enhance the support for the streaming data originating from IoT devices that give real-time data that requires real-time analyses. Improved connectors and APIs shall improve data ingestion and processing in real-time, hence improving how quickly Spark pulls off high-velocity data (Dwivedi et al., 2023). In addition, the exact integration with the cloud will also be improved in Spark, where Cloud platforms will take charge of ample data storage and processing. This involves more robust integration with cloud-native storage, data warehousing, and analytics services from AWS, Azure, and Google Cloud. Also, Spark will leverage other types of databases, such as NoSQL, graph, and blockchain databases, to enable the user to conduct analytics on different types and structures of data. Thus, Spark will allow organizations to offer the maximum value from the information they deal with, regardless of its source and form, providing more comprehensive and timely information.
d. Cloud-Native Features
Since cloud computing is becoming famous, Apache Spark is also building inherent compatibility for cloud-based environments that makes its use in cloud environments easier. The updates focusing on the cloud surroundings are the Auto-Scaling Services for the provisioning and configuring tools that simplify the deployment of Spark Clusters on cloud solutions (Simplilearn, 2024). These tools will allow integration with cloud-native storage and compute resources and allow users to grow their workloads on the cloud. New possibilities in resource management will enable the user to control and allocate cloud resources more effectively according to their load, releasing resources in case of low utilization and adapting costs and performance characteristics in this way. Spark will also continue to provide more backing to serverless computing frameworks, enabling users to execute Spark applications without handling the underlying infrastructure. This serverless approach will allow for automatic scaling, high availability, and cost optimization since users only pay for the time the computing resources are used. Improved support for Kubernetes, one of the most popular container orchestration systems, will strengthen Spark's cloud-native features and improve container management, orchestration, and integration with other cloud-native services (Dwivedi et al., 2023). These enhancements will help to make Spark more usable and cost-effective for organizations that are using cloud infrastructure to support big data analytics while at the same time reducing the amount of overhead required to do so.
e. Broader Language Support
Apache Spark is expected to become even more flexible as the support for other programming languages is expected to be added to the current list of Scala, Java, Python, and R languages used in Spark development. Thus, by including languages like Julia, which is famous for its numerical and scientific computing performance, Spark can draw developers working in specific niches that demand high data processing (Simplilearn, 2024). Also, supporting languages like JavaScript could bring Spark to the large community of web developers, allowing them to perform big data analytics within a familiar environment. The new language persists in compatibility to integrate Spark's various software environments and processes that the developers deem essential. Besides, this inclusiveness increases the span of control, thereby making extensive data analysis more achievable, while the increased number of people involved in the Spark platform ideas fosters creativity as more people get a chance to participate as well as earn from the platform (Dwivedi et al., 2023). Thus, by making Spark more available and setting up the possibility to support more programming languages, it would be even more embedded into the vast data platform, and more people would come forward to develop the technology.
f. Cross-Platform and Multi-Cluster Operations
In the future, Apache Spark will experience significant developments aimed at enhancing the long-awaited cross-system interoperability and organizing several clusters or the cluster of one hybrid or multiple clouds in the future (Dwivedi et al., 2023). Such improvements will help organizations avoid having Spark workloads run on one platform or cloud vendor alone, making executing more complex and decentralized data processing tasks possible. The level of interoperability will be enhanced in a way that there will be data integration and data sharing between the on-premise solutions, private clouds and public clouds to enhance data consonance (Simplilearn, 2024). These developments will offer a real-time view of the cluster and resource consumption, which will help to mitigate the operational overhead of managing distributed systems. Also, strong security measures and compliance tools will guarantee data management and security in different regions and environments (Dwivedi et al., 2023). With cross-platform and multi-cluster capabilities, Spark will help organizations fully leverage their data architecture, allowing for more flexible, scalable, and fault-tolerant big data solutions that meet the organization's requirements and deployment topology.
g. More robust Growth of community and Ecosystem
Apache Spark's future is, therefore, closely linked with the health of the open-source ecosystem, which is central to the development of Apache Spark through contributions and innovations. In the future, as more developers, researchers, and organizations use Spark, we can expect to see the development of new libraries and tools that expand its application in different fields (Simplilearn, 2024). Community-driven projects may promote the creation of specific libraries for data analysis, machine learning, and other superior functions, making Spark even more versatile and efficient. These should provide new features and better performance, encourage best practice and comprehensive documentation and make the project approachable for new members if and when they are needed. The cooperation will also be healthy in developing new features for real-time processing and utilising other resources and compatibility with other technologies, as noted by Armbrust et al., 2015. The further development of the Ecosystem will entail more active and creative users who can test and improve the solutions quickly. This culture of continual improvement and expansion of new services will ensure that Spark continues to evolve; it will remain relevant today and in the future for big data analytics and will remain desirable for the market despite the dynamics of the technological landscape.
Conclusion
Despite significant progress, Apache Spark has numerous difficulties associated with big data and machine learning problems when using flexible and fault-tolerant structures: serialization, memory, and giant clusters. Nonetheless, there are a couple of factors that have currently impacted Spark. Nevertheless, the future of Spark is quite bright, with expectations of having better features in machine learning, better performance, integration with other data sources, and the development of new features in cloud computing. More comprehensive language support, single/multiple clusters, more cluster operations, and growth of the Spark community and Ecosystem will further enhance its importance in big data and AI platforms. Thus, overcoming these challenges and using future progress, Spark will go on to improve and offer improved and more efficient solutions in different activities related to data processing and analysis.
References
- Armbrust, M., Xin, R. S., Lian, C., Huai, Y., Liu, D., Bradley, J. K., ... & Zaharia, M. (2015, May). Spark SQL: Relational data processing in Spark. In Proceedings of the 2015 ACM SIGMOD international conference on management of data (pp. 1383-1394).
- Dwivedi, Y. K., Sharma, A., Rana, N. P., Giannakis, M., Goel, P., & Dutot, V. (2023). Evolution of artificial intelligence research in Technological Forecasting and Social Change: Research topics, trends, and future directions. Technological Forecasting and Social Change, p. 192, 122579.
- Elshawi, R., Sakr, S., Talia, D., & Trunfio, P. (2018). Extensive data systems meet machine learning challenges: towards big data science as a service. Big data research, 14, 1-11.
- Ksolves Team (2022). Apache Spark Benefits: Why Enterprises are Moving To this Data Engineering Tool. Available at: https://www.ksolves.com/blog/big-data/spark/apache-spark-benefits-reasons-why-enterprises-are-moving-to-this-data-engineering-tool#:~:text=Apache%20Spark%20is%20rapidly%20adopted,machine%20learning%2C%20and%20fog%20computing.
- Nelamali, M. (2024). Different types of issues while running in the cluster. https://sparkbyexamples.com/spark/different-types-of-issues-while-running-spark-projects/
- Nguyen, G., Dlugolinsky, S., Bobák, M., Tran, V., López García, Á., Heredia, I., ... & Hluchý, L. (2019). Machine learning and deep learning frameworks and libraries for large-scale data mining: a survey. Artificial Intelligence Review, 52, 77-124.
- Pointer. K. (2024). What is Apache Spark? The big data platform that crushed Hadoop. Available at: https://www.infoworld.com/article/2259224/what-is-apache-spark-the-big-data-platform-that-crushed-hadoop.html#:~:text=Berkeley%20in%202009%2C%20Apache%20Spark,machine%20learning%2C%20and%20graph%20processing.
- Sewall, P., & Singh, H. (2021, October). A critical analysis of Apache Hadoop and Spark for big data processing. In 2021 6th International Conference on Signal Processing, Computing and Control (ISPCC) (pp. 308–313). IEEE.
- Simplilearn (2024). The Evolutionary Path of Spark Technology: Lets Look Ahead! Available at: https://www.simplilearn.com/future-of-spark-article#:~:text=Here%20are%20some%20of%20the,out%2Dof%2Dmemory%20errors.
- Tang, S., He, B., Yu, C., Li, Y., & Li, K. (2020). A survey on spark ecosystem: Big data processing infrastructure, machine learning, and applications. IEEE Transactions on Knowledge and Data Engineering, 34(1), 71-91.
0 人喜欢
暂无评论,来发布第一条评论吧!