


The Integration and Impact of AI Spark Big Models in the Healthcare Industry
Introduction
In the recent past, the healthcare industry has dramatically transformed following the invention and integration of more advanced technologies used in data generation with the aim of enhancing healthcare practices (Shrotriya et al., 2023). These technological advancements have effectively propelled the healthcare industry forward especially in generating and analyzing healthcare outcomes. This substantial achievement can be attributed to the continuing development of technological devices in medicine, electronic health records, and the use of wearable gadgets that have recently boosted its trend. Patel and Sharma (2014) noted that Big Data has become a potent instrument with the potential to revolutionize healthcare and stimulate innovation in several industries. Apache Spark has emerged as one of the critical solutions to these challenges by supporting services and service components equipped with data processing and analysis features. Salloum et al. (2016) defined Apache Spark as an open-source distributed computing system that primarily manages big data processing tasks. It works based on in-memory computations and efficient query processing to quickly process large volumes of information. This paper analyses all the facets of the AI Spark Big model for enhancing healthcare industries' services, primarily through analyzing Apache Spark.
1. HealthCare Digitalization through the Spark Model
Electronic medical records (EMRs) and electronic health records (EHRs) are the primary frameworks for building up the patients' necessary clinical and medical-related information as they work towards enhancing the quality of the health care service, promoting the efficiency of the service delivery, enhancing control and reduction of costs and more importantly, reducing medical mistakes (Han & Zhang, 2015). The patients' EMR genomics include the genotyping and gene expression details, payer-provider affiliation information collected through genomics, prescription medications, insurance data, and related IoT devices, which contribute to enhancing the healthcare industry (Bedeley, 2017). On a positive note, it is also significant to acknowledge advancements in developing and deploying well-being monitoring solutions. Such systems consist of software and hardware with predictive capabilities. These tools can recognize that a certain patient is at risk, setting off audible alarms in that context and notifying the appropriate caregivers. The tools produce tremendous information, providing the principal clinical or medical response. the following are some measures whereby Spark has enhanced service delivery in the healthcare sector;
a. EHRS Management
According to Ansari (2019), knowing the significance of EHRs in present healthcare facilities, physicians and nurses can enter, retrieve, view, or share patients' records and information with other clinicians through the EHR systems. There are several challenges in data processing and storing data within EHRs because the volume and the types of data are also huge, and the access to these data must be timely. This remains a significant challenge when managing EHR for large patient populations, populations, and requires an appropriate solution. Apache Spark has played fundamental roles aimed at addressing these challenges following its ability to efficiently manage data and analytics. For example, Apache Spark has played a significant role in enhancing healthcare organizations by strengthening the connection of several players and to improving exchange between them (Ansari, 2019). Notably, Apache Spark has addressed EHR through different real-life situations Apache Spark.
b. Disease outbreak forecasting
Awareness and early intervention of diseases translate into an appreciation of the magnitude and extent of protection required to safeguard the populace and the efficient use of limited resources in the health sector (Shrotriya et al., 2023). The accuracy of an expected disease outbreak in a given population can be enhanced by assembling information from other sources, including public health, social networks, and the environment. When used with the current machine learning techniques, Spark helps healthcare organizations refine the prediction of an epidemic depending on the forecast's time and accuracy.
c. Genetics and Personalized Medicine
In the concept of personalized medicine, the objectives set are the enhancement of the interventions' precision and efficacy as a result of the use of the patient's genotype. However, managing, reviewing, and using data in genomics research have relatively become cumbersome due to the large volumes of mess and complex data streams produced (Shrotriya et al., 2023). Apache Spark has a deeper achievement in a genomic study where extensive analysis and variance exploration have been done. Specific case studies provided in the literature reviewed have pointed out that Apache Spark has a highly impactful role in promoting personalized medicine and patient care.
d. Analysis of Medical Imaging
Imaging diagnosis is one of the critical areas of diagnosis in healthcare and involves methods such as radiography, magnetic resonance imaging, and computed axial tomography scans. Help is needed to manage all this medical imaging data, and it is a relatively necessary and valuable analysis by healthcare workers and professionals. Incorporating Apache Spark in photo processing and deep learning frameworks may bring significant changes in medical image analysis that can significantly improve the picture recognition approach (Shrotriya et al., 2023). These are why these abilities contribute to faster decisions on treatment regimens and improved diagnostics. Some real-life examples include the following: The application of Apache Spark in medical image processing has improved patient treatment and increased medical productivity.
e. Telemedicine and Remote Patient Monitoring
Recently, telemedicine and remote patient monitoring have been discovered as trends, enabling healthcare staff to provide treatments and oversee the patient's physiological data from a distance. Issues within this domain include the issue of large volumes of data as probed by remote monitoring devices and the need to implement the findings in real time. Spark is also helpful in identifying potential threats to health, improving the quantity and quality of healthcare services, and providing immediate data processing and analysis necessary in telemedicine practice. Case studies revealed research proving that Apache Spark can enhance telemedicine services and RPM systems. This could improve the quality of patients' care and healthcare delivery systems.
2. Apache Spark in Medical Imaging Analysis
The application of Apache Spark in medical imaging analysis can be deemed a revolution in the healthcare industry. Apache Spark has been argued to be the most suitable distributed computation engine for processing big image datasets (Tang et al., 2020). Diagnostic imaging evaluation entails considering many imaging methods, including X-ray, CT scan, and MRI scan, CT, and MRI, to discover features that point toward certain disease conditions or health complications. The enhancement of specialized processors and analysis capabilities for managing big data has become even more important in the latest and advancing developments in medical imaging data (Shrotriya et al., 2023). Analyzing medical pictures is relatively trivial as long as the topic concerns Apache Spark, as it incorporates features I have mentioned above, including in-memory processing, fault tolerance, and scalability. For academic and healthcare professionals, Spark can fundamentally support the excessive number of image sets to enhance diagnosis and tools. Also, implementing Spark will not affect the existing chains of respective processes in healthcare institutions since it is fully interoperable. Here, it shall be illustrated how, through Spark, the strength of the picture analysis and its consequences are supported.
a. Reduction in Hospital Readmission
Apache Spark has focused on delivering a premium reduction in readmission volume in the healthcare sector. Hence, increased readmission rates contribute to improved costs in the health system with that despaired outcome for the patient. Components such as electronic health records, demographic data, and other pertinent facets have been incorporated into healthcare organizations by analyzing the data to identify factors indicative of or may lead to hospital readmissions using Apache Spark. In detail, medical providers can harness extensive data analysis powered by Spark and machine learning algorithms to have a clearer picture of the patients most suitable for readmission and an improved approach that can minimize such cases across healthcare facilities (Shrotriya et al., 2023). The application of the analytics based on Apache Spark positively affects the high readmission rates of hospitals, and the outcomes are profitable for both patients and the scientific-healing complex.
b. Early Detection of Sepsi
Sepsis, if not detected at an early stage, should be treated immediately to avoid organ failure or even death. Sepsis, which the authors claim might result in death, starts with an infection and initiates an inflammatory response in the body (Lelubre & Vincent, 2018). Apache Spark is instrumental in rapid sepsis identification since it can analyze clinically relevant real-time data, including the patient's temperature, heart rate, blood pressure, glucose levels, and most routine laboratory results. Spark is intended to utilize machine learning to assist clinicians in discerning the indications of sepsis and prescribing the appropriate treatment immediately (Shrotriya et al., 2023). Apache Spark has been tested in various studies to be efficient in diagnosing sepsis early, enhancing t, treatment with minimal lethality.
c. Cancer Studies and Treatment Optimization
Apache Spark has transformed the analysis of cancer and the management of treatment procedures. Using available knowledge of the nature of cancer, namely the fact that it is a multifactorial disease associated with a vast amount of genomic, proteomic, and clinical data, one can state that cancer poses severe challenges and limitations to both scholars and clinicians. Apache Spark assists in improving the time taken for searching biomarkers, subtypes, and probable treatment solutions for cancer using big data analyzing lenses and speedy processing (Shrotriya et al., 2023). Moreover, by integrating AI and machine learning, Spark has eased the ability to formulate concrete strategies that enhance cancer therapy prospects without worsening side effects.
d. Accelerating Drug Discovery
As with conventional drug molecules, developing new drug molecules in the chemical and pharmaceutical industry can be time-consuming, expensive, and labor-intensive. It is incredibly vital in finding new drugs since it helps in understanding a wide of information in the form of chemicals and genomic and proteomic databases. The function and power of advanced Analysis in Spark allow researchers to discover new drugs that can cure diseases or even predict the side effects of particular medications. Machine learning and AI have benefited drug discovery because they offer more accurate estimations about how a given drug interacts with a target. In multiple cases, it has been described how the application of Apache Spark increases the speed of drug discovery operations to a great extent, thus improving the continuing development of new drugs and the treatment of patients.
3. The Impacts of Apache Spark in the Management of Health Population
It has been crucial to have the Apache Spark in population health application. Spark, an advanced big data distributed computing framework, can address the challenges of big data about population health. Shrotriya and colleagues (2023) argues that Apache Spark as a possible solution for enhancing research findings and the utility of data in decision-making on population health intervention. Specifically, the new objectives of population health management will require the analysis of large volumes of data to detect patterns, developments in, and degrees of 'healthiness' within groups. Therefore, this data is applicable in establishing measures to counter various public health issues, allocating funds, and executing early interventions.
Population data is rich and complex, so advanced functions for working with populations and large data sums are necessary (Gopalani & Arora, 2019). Apache Spark is a prime illustrated example characterized by several features, including its scalability, fault tolerance, and the ability to process big data in memory; these qualities make it possible to manage the entire population's health. Namely, by manipulating and analyzing Big Data in a health context, PH practitioners and researchers can discover relationships and patterns for evidence-based decision-making with the help of Spark. As a component of population health management in today's environment, Spark is easy to integrate into current practices due to its ability to handle many languages and data sets (Shrotriya et al., 2023). In addition to enhancing our knowledge of the factors that define the results concerning public health, machine learning technologies are suitable for creating high-level processing models for evaluating the population's condition. Below is a description of the ways by which the implementation of Apache Spark in the population health management process can make a significant impact on public health.
4. Technological Advancements and Integration
Together with other advancements in the technology and compatibility of Apache Spark with the Industry standards, their applicability in improving the operations of healthcare structures has been enhanced to a greater extent. Several significant developments that have achieved regarding a substantial role in the spread of Spark in healthcare. One od these developments include machine learning libraries. This has boosted the work of the organization in improving innovations that are data-driven and patient service delivery. MLlib is one of the ten important machine learning libraries in Spark, and it has played crucial roles in contributing to the latter's growth in the healthcare sector (Nazari et al., 2019). These libraries provide ample coverage for dimensionality reduction, grouping, regression, and classification tasks. As illustrated in Figure 1, these resources are employed by academics working alongside healthcare professionals in building sophisticated models for the prognosis of the results for patients, for following ailment trends, and for modeling the interdependencies between the numerous health indicators. Some programming languages Spark supports are interoperability-friendly, particularly regarding integration into existing health functions. Some of them are R language, Python language, Java language, and Scala language. Such flexibility means that Spark can work concurrently with the other structures within healthcare organizations without disrupting the existing system. Thus, the problems that emanate from integration are considerably eased (Shrotriya et al., 2023).
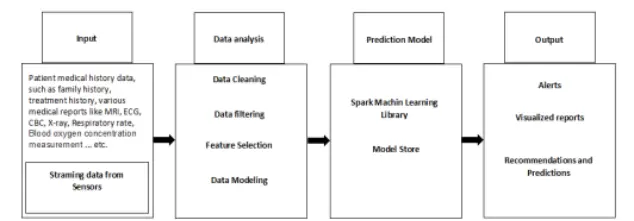
Figure 1 Illustration of the proposed ML framework for Spark.
Ethical Considerations
There are many universal topics that will continuously become important to adopting big data technologies like Apache Spark, especially now that healthcare organizations are embracing such technology; these are data privacy security and fairness issues. It becomes imperative that there are ethical principles that govern the use, analysis, and reporting of data, which enables the correct application of new technological tools in the health sector. While there is potential for using healthcare data analytics in the future, there are always ethical issues involved, which could be solved if there are guidelines and regulations to govern moral concerns via transparency and acceptance of responsibilities, positive results could be achieved (Zaharia et al., 2016). Hence, the healthcare business has to consider the ethical issues and use big data technologies, such as Apache Spark, properly and sustainably to enhance trust with the specific patient and stakeholder. Based on the description of Apache Spark, this could easily mean that the healthcare business could greatly benefit from Apache Spark by having extra processing and analysis functions. However, there are certain constraints within the platform that we need to address, as the utilization of this platform is rare at the moment. The significant challenges experienced by healthcare businesses incorporating Spark include the security and privacy of the information processed and analyzed and the requirement for skilled personnel to invest in it.
Since the information content is processed in the context of the healthcare sector, it is nearly imperative to maintain the data's security, especially regarding the industry's strict compliance with data privacy when integrating Spark. Particular attention should be paid to traditional data in Spark to avoid violating the norms of critical current legislation, such as HIPAA. Because the data in the raw form and transit and transform within applications can contain susceptible information, businesses should embrace such measures as encryption, access control, and auditing trails. Nonetheless, Spark has brought other challenges to privacy practice within the healthcare sector, even as it continues to improve efficiency by processing data in real-time.
Conclusion
Apache server Spark affects innovations in the healthcare business to a significant extent, enhances the quality of patient care, and optimizes decision-making based on big data analytics. Due to Spark's consistent extensibility, Spark incorporates sophisticated machine learning frameworks to address these issues, which elaborate the handling of comprehensive and intricate data in healthcare organizations that could benefit healthcare firms. Of course, Spark can be helpful in other fields like medical image processing and analysis, genomic research, disease surveillance, and population health management. Before going into the successful implementation of Spark in the healthcare field, three major concerns should be solved, and these are: However, for firms to gain full benefits of what Spark can offer, some guidelines must be laid down to ensure that sensitive data is well protected and meets the set laws regulating healthcare firms. The skills gap could be addressed by concentrating on the qualities of investment in practices of getting and developing a healthcare workforce that could employ Spark by promoting the culture of lifelong learning of employees.
References
- Bedeley, R. T. (2017). An Investigation of Analytics and Business Intelligence Applications in Improving Healthcare Organization Performance: A Mixed Methods Research. The University of North Carolina at Greensboro.
- Gopalani, S., & Arora, R. (2019). You are comparing Apache spark and map-reduce with performance analysis using k-means—International Journal of Computer Applications, 113(1).
- Han, Z., & Zhang, Y. (2015, December). Spark: A big data processing platform based on memory computing. In 2015 Seventh International Symposium on Parallel Architectures, Algorithms and Programming (PAAP) (pp. 172-176). IEEE.
- Patel, J. A., & Sharma, P. (2014, August). Big data for better health planning. In 2014 International Conference on Advances in Engineering & technology research (ICAETR-2014) (pp. 1-5). IEEE.
- Salloum, S., Dautov, R., Chen, X., Peng, P. X., & Huang, J. Z. (2016). Big data analytics on Apache Spark. International Journal of Data Science and Analytics, 1, 145-164.
- Shrotriya, L., Sharma, K., Parashar, D., Mishra, K., Rawat, S. S., & Pagare, H. (2023). Apache Spark in healthcare: Advancing data-driven innovations and better patient care. International Journal of Advanced Computer Science and Applications, 14(6).
- Zaharia, M., Xin, R. S., Wendell, P., Das, T., Armbrust, M., Dave, A., ... & Stoica, I. (2016). Apache spark: a unified engine for big data processing. Communications of the ACM, 59(11), 56-65.
1 人喜欢

There is no comment, let's add the first one.